Wil je weten hoe een gamejam gaat? Of hoe je er een aan zou kunnen pakken? Ik kon maar met moeite ervaringen van anderen vinden. Dus bij dezen, mijn ervaring met de GlobalGameJam.org gamejam in januari 2019.
Dag 1
15:30 Cibap Zwolle
Ik doe dit jaar mee aan de GlobalGameJam.org gamejam, en ben opweg naar de start bij Cibap in locatie Zwolle. Het programma geeft aan 15:00 inloop, 16:30 start programma. Door een doolhof van gangen zoek ik mijn weg. Ik blijk de verkeerde ingang genomen te hebben, loop t hele gebouw door naar de andere ingang. Daar vind ik de tafel voor inschrijvingen.
25 man ingeschreven, ruimte voor 75 man. Na de eerste kennismaking blijkt dat een aantal naar andere locaties van de gamejam wilden gaan maar dat die vol zaten. Zwolle heeft maar een beperkte game development scene.

17:00 Kickoff
Van 17:00 tot 18:30 hebben we de start van het programma. We verzamelen ons in een grote zaal met podium. Na een korte intro van de leidende personen en de huisregels krijgen we een filmpje te zien van GlobalGameJam.org. Rami Ismail heeft het over tekenen, dat iedereen een koe kan tekenen, of er anders een pijltje bij kan zetten met ‘koe’. Ik raak geïnspireerd. De intro sluit af met het thema, gebracht door 2 dames die duidelijk onwennig voor de camera een stukje opvoeren over hun gevoel van ‘thuis’.
Dan volgen er een paar team activiteiten. “Om te bepalen welke personen en eigenschappen elkaar aanvullen.” Eerst een snelle check hoeveel tekenaars/ontwerpers er rondlopen. Er blijkt een team te zijn wat al een vaste samenstelling heeft, 3 artistieke mensen en 1 ontwikkelaar. Maar twee artistieke mensen zijn beschikbaar als team-loos. En nog eens 14 ontwikkelaars. Dat begint goed denk ik.
19:00 diner
Vanaf 19:00 is het diner. Het duurt even, maar na een tijdje arriveert het eten in de vorm van lasagne en spaghetti carbonara. Dat was goed eten. De teams moeten gevormd worden. Veel passiviteit, kan ook niet anders vanwege het overgrote deel aan studenten die toch een beetje onzeker zijn over hun kunnen en wat ze willen. Ik begin gewoon mensen te zoeken. De oudste persoon ter plaatse, Kees, is mijn eerste teamlid. 45 jaar, beheerder bij een recent gesloten ziekenhuis, en nu bezig een carrière in game development te starten. Ik vind nog een andere ontwikkelaar, Peter, en nog een ontwikkelaar/artiest genaamd Jan. Allebei studenten. Daarna gaat ieder team naar een eigen ruimte.
20:00 The first mile
Aangekomen in onze ruimte claim ik de leiding. Recent heb ik bij de NS een 2-tal design sprints gevolgd: 1 week lang intensief samenwerken met alle benodigde disciplines van een ontwikkeltraject en gezamenlijk via een creatief proces het te bouwen product bepalen. Dat wilde ik ook hier gaan doen. In de hoop dat ik zou kunnen oefenen in een neutrale faciliterende rol als spelverdeler.
Via een aantal stappen van ideevorming / reductie hebben we bepaald wat wij met elkaar willen bouwen. Tot 23:00 waren wij bezig om plannen te maken. Geen code aangeraakt. Wel veel besloten. Het concept van de designsprint werkt tot nu toe, alleen wel weinig ‘gebouwd’. Hopelijk betaalt het zich terug.

stap 3, getekende gameplay aan elkaar uitleggen 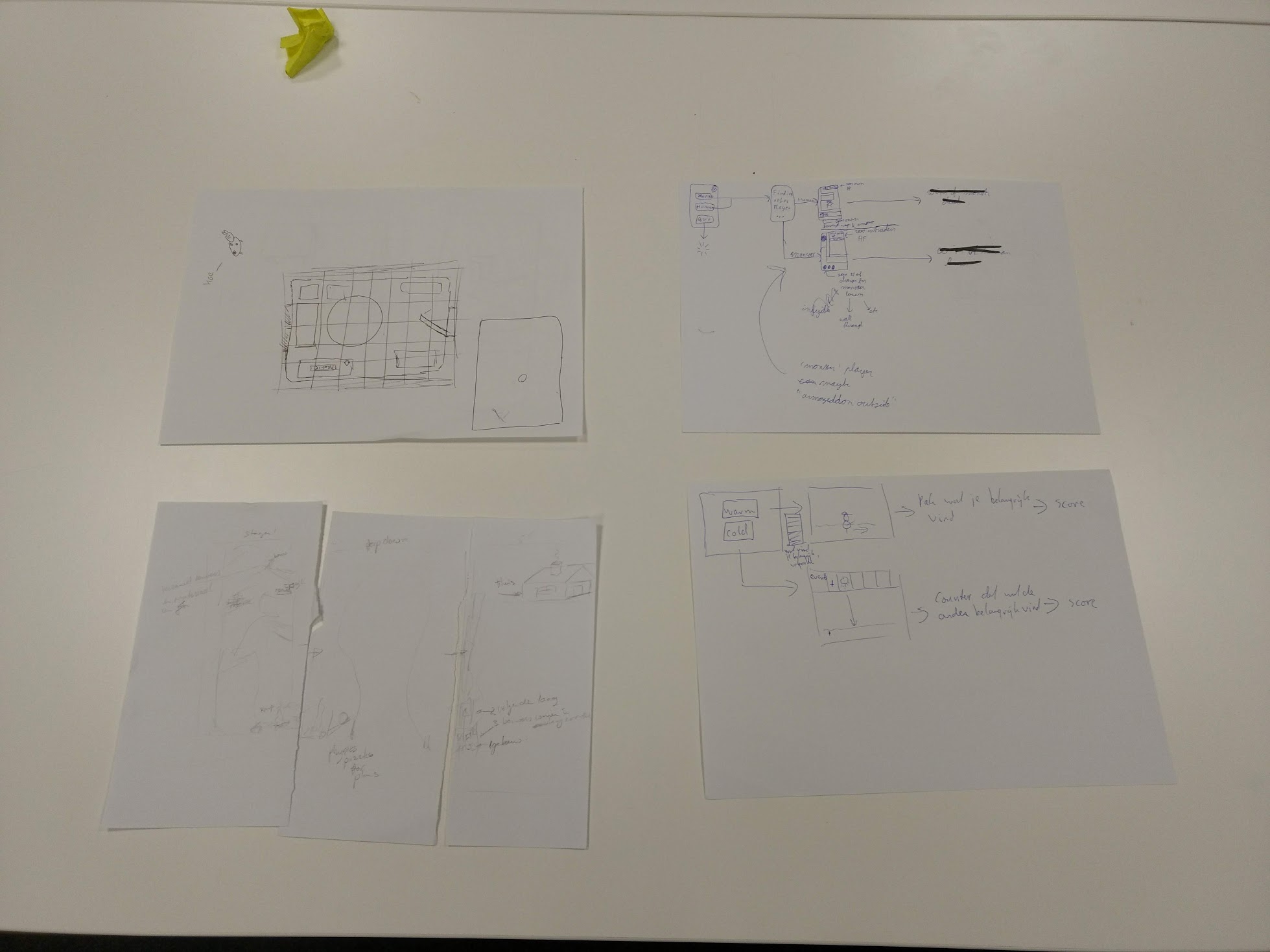
stap 2, concept uittekenen 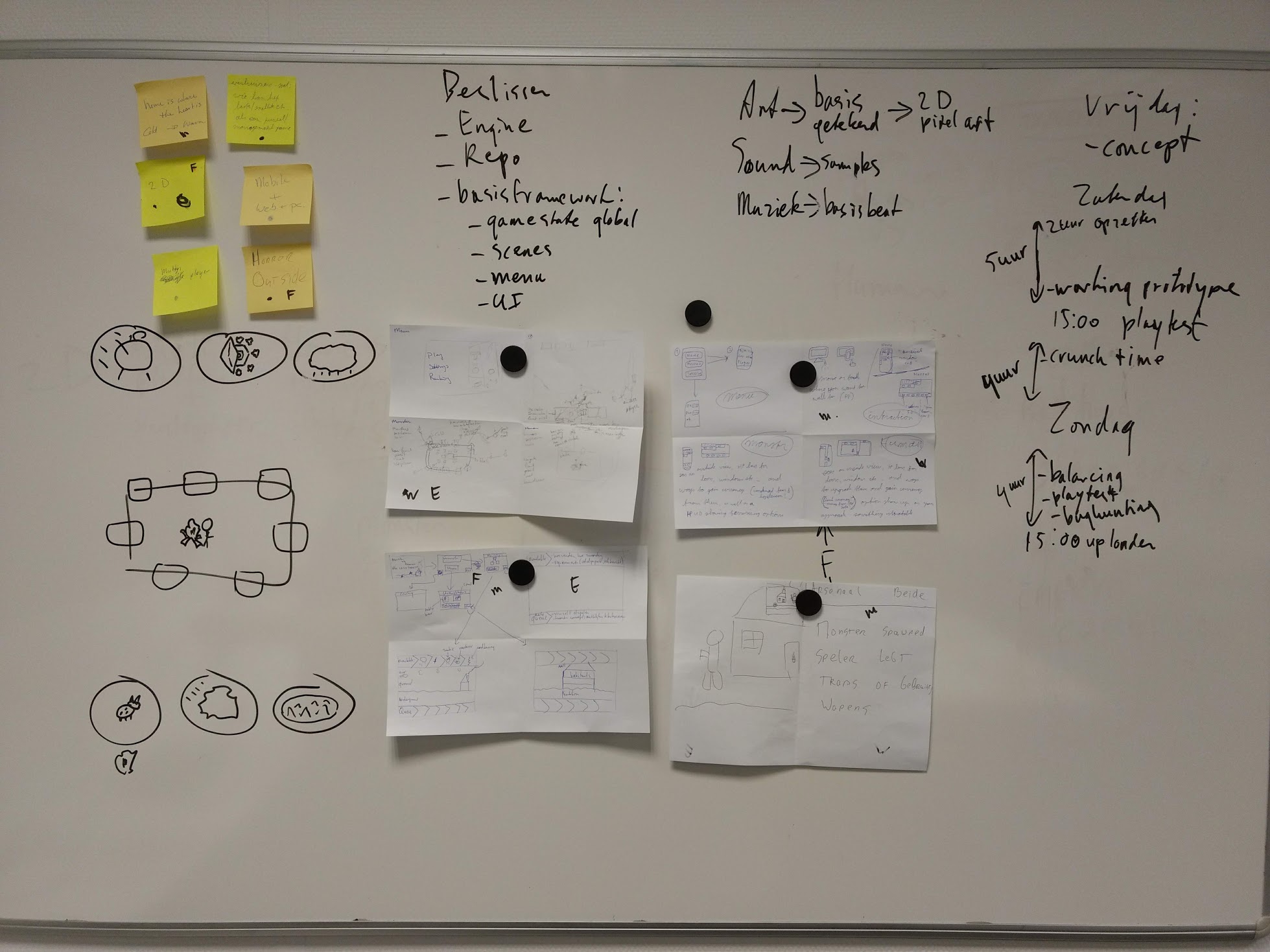
stap 4, meest zinvolle gameplay elementen verzamelen
23:00 we call it a day
We breien er een einde aan voor de dag. De meeste teamleden gaan weer naar huis om daar te slapen. Kees maakt gebruik van de slaapplekken die hier op locatie zijn. Kees geeft ook aan dat hij wel de scaffolding op wil zetten in Unity ergens in de komende uren, als hij een momentje vindt naast t slapen.
Dag 2
07:20 thuis, opstaan
Ik had wat moeite met opstaan. Op de heenweg nog even langs de winkel, extra snacks voor tijdens de jam. Niet dat we per se eten en drinken moesten halen, daarin werden we goed voorzien op de locatie, maar toch. Een paar snacks in handbereik leek mij een goed plan. Net zoals paracetamol. Want ik had toch wel last van hoofdpijn door spanning.
09:00 Cibap Zwolle, ontbijt
Ik kom om 9:00 aan. Het ontbijt was van 08:00 tot 10:00, ik bleek vroeg. Er staat brood en beleg klaar. Ik werk snel een broodje naar binnen.
Aan t werk. Kees was blijven slapen op locatie. Helaas voor Kees maar gelukkig voor ons kon Kees niet slapen en heeft hij in de nacht een paar dingen opgezet. Jan kwam rond 10 uur aan.
Peter had moeite met het OV richting Zwolle te geraken. Wat ik best kan begrijpen. Jan en ik hebben t gemak van een auto en in de buurt wonen, met t OV introduceer je meteen moeilijkheden als je in t weekend vroeg ergens wilt zijn.
Ik probeer het team wat leiding te geven door gezamenlijk korte termijn doelen op te laten stellen. We stellen ons als doel om een basis game neer te zetten tot 13:30.

We gaan voor een gewaagd concept: 2 teams moeten een huis veroveren of verdedigen. T liefst is dit multiplayer te spelen op mobile. En we willen de gameplay asynchroon maken, dus een totaal andere ervaring als je team A of B bent.

We beginnen maar wat te bouwen in Unity. Want hoewel we nog niet helemaal duidelijk hadden wat we gingen bouwen, realiseerden we ons dat we toch echt wel met de code aan de slag moesten. Ik had uitgerekend dat de jam 13 uur aan bouwen beschikbaar had. Dat krijg je als je een 48 uurs jam neemt en het grootste gedeelte van de tijd slaapt en neven activiteiten uitvoert…
Tussendoor maak ik onze pagina op de globalgamejam.org site. De game krijgt de naam ‘cozy home – human vs other’. We hebben wat problemen om te bepalen tegen wie je nu precies het opneemt. (Het is uiteindelijk https://globalgamejam.org/2019/games/cozy-home-human-vs-cowman geworden, maar dat wisten we toen nog niet.)
We ontdekken dat Unity zijn (simpele) netwerkoplossing aan het uitfaseren is. Omdat het team weinig kennis heeft op dit gebied, met alleen Kees die er eens een Udemy cursus over gevolgd heeft, zien we multiplayer als een steeds groter wordend risico. Na een kort beraad stellen we een simpele random AI voor als tijdelijke placeholder voor t gedrag van de tegenstander, zodat we niet vastlopen als we geen networking voor elkaar krijgen.
Ik heb niet veel kunnen programmeren vanwege al t organiseren en dingen regelen. Mijn bijdrage deze ochtend aan de code was een basis gameplay flow van menu-selectie-game-ending.

13:30 Lunch
We worden gevraagd om naar de lunch te komen. Eigenlijk zijn we best tevreden: we hebben een basis game staan met een menu, level, rond lopend mannetje (‘human’), een huisje en een ending.
Er staan belegde broodjes voor ons klaar. Dat is goed geregeld!
14:00 Lekker jammen
We gaan ons en ons spel voorbereiden voor de eerste playtest.

Een paar ideeën moeten nog geverifieerd worden. Ik stel een papieren playtest voor om de asymmetrische gameplay te testen want die is heel duur om te bouwen en moet wel werken. Verder kwamen we in discussie of een overlord minion aansturende situatie wel genoeg binding met een huis op zou leveren (en dus home gevoel), dus dat was ook iets wat we gingen testen.
We beginnen ons ook te realiseren dat we ook een extra ending kunnen introduceren die het concept veel sterker maakt: de obvious ending is dat je elkaar uit huis jaagt, de niet-obvious is dat je er samen uit komt.
15:00 Playtesting
Wij waren het eerste team aanwezig in de gemeenschappelijke ruimte. Ik heb er alle vertrouwen in omdat ik de papieren playtest uitvoer. We doen ook een playtest van de unity game op een van onze laptops. Kort schiet het door mijn hoofd dat ik eigenlijk niet echt goed heb opgelet of onze game (dat waar het om draait, lol), eigenlijk wel lekker genoeg aanvoelt. Maar ik ga t prototype bedienen, Kees bedient de game en heeft er de laatste fixes op toegepast.

De playtest. Het gevoel van thuis bleek het beste bij geen afstandelijkheid (geen minion AI, geen afstandelijke overlord). Tijdens de playtest werd duidelijk dat de alternatieve ending een grote pre zou opleveren. Verder merkten wij dat mensen gebalanceerde maar hard-hitting acties leuk vinden. We kregen ook feedback waar we niet om gevraagd hadden: voor velen was er t gevoel dat de human onvermijdelijk gaat winnen bij het binnentreden van het huis, en dat de andere partij hoogstens een delay kan veroorzaken.
De paper prototype werd door veel mensen als heel leuk ervaren. Gewoon een beetje rollenspel spelen. En t was maar goed dat we dat hadden, de game zelf wist minder te trekken. Dat de game niet echt trok viel mij niet op omdat ik de paper prototype bediende, maar achteraf gezien waren hier al signalen dat we gameplay wise niet sterk stonden met onze game.
15:30 Aan t werk
De playtest liep tot 16:00, om 15:30 hadden wij al genoeg info.
We stelden weer nieuwe doelen op. Multiplayer zat er voor nu niet meer in. Wel content, veel meer content.
En natuurlijk geen asymmetrische gameplay: besturing en aanzicht aan beide kanten t zelfde, wel wat verschil qua doel en actions. Een groot voordeel want de UI en interactie systeem zou daarmee herbruikbaar worden.


18:00 diner
Het eten komt vroeg voor ons gevoel. Er is nog zo veel te doen. Waar wij bij de playtest nog dachten goed op weg te zijn beginnen we ons nu te realiseren hoe veel er nog moet gebeuren. Effectief gezien zouden we vanaf nu nog maar 6 bouw uren beschikbaar hebben. (Tenzij we op slaap gingen bezuinigen of niet meer mee doen met de gemeenschappelijke activiteiten)
Toch maar eten. Het diner smaakt goed. Lekker Hollandse pot (hutspot en/of stampot, rookworst en gehaktballen). Als team beginnen we al wat beter op elkaar ingespeeld te raken. De tongen zijn losser en we hebben leuke gesprekken.
Na het eten snel weer terug naar onze ruimte. Zo langzamerhand weet iedereen wel wat hij moet doen en komt er minder druk bij mij als spelverdeler te liggen.
Maar we worden al snel onderbroken door de leiding van de gamejam. Er is een gemeenschappelijke gebeurtenis gepland.
19:30 Potten en pannen
Met wat tegenzin begeven we ons naar de gemeenschappelijke ruimte. Daar treffen wij jambe’s aan. En een hele inspirerende instructeur.

Een uur later, met dikke rode handen, gaan we weer aan t werk. Ik merk dat ik ontspannen ben geraakt van zo’n sessie lekker rammen, dit is iets heel anders dan t programmeer/denk werk.
20:30 meters
We hebben inspiratie. Iedereen weet wel iets om mee aan de slag te gaan. De playtesten hadden leuke resultaten waar we iets mee kunnen.
Zo introduceren we de koe-man ipv duivel, zodat spelers zich beter in kunnen leven. We willen dat beide speelbare kanten een goed home-gevoel kunnen opwekken bij de menselijke spelers. Ons spel heet nu officieel ‘cozy home – human vs cowman’.
Qua werk probeer ik meer in mijn flow te komen. Ik ga de code-behind voor alle cowman dingen bouwen. Tot nu toe hadden we alleen de human kant, dus dit wordt een kopie van die kant plus een ingewikkeld switch mechanisme waarmee je kan wisselen tussen human/cowman maar ook tussen aanvallen/verdedigen.
Ik probeer aan te sluiten bij de heersende programmeer stijl. K heb de hele dag al moeite om erin te komen. Kees heeft al zijn ervaring uit zelfstudies, t zijn geen goede programmeer stijlen maar wie ben ik: als t werk dan werkt het. Vooral als we maar weinig tijd hebben dan wil ik mensen niet uit hun flow halen.
Wat betreft de werkwijzen: Peter werkt hetzelfde als Kees. Peter en Kees maken echt de meters in code. Jan maakt vooral de art, en hangt af en toe wat in elkaar in de Unity designer zoals een nette animatie. Jan blijkt behoorlijk kundig in 2D pixelart.
De game code is een mix van service locater patterns en object-naam gebonden zoekacties. Ik ben onzeker of ik hier wat van moet vinden. Ikzelf zou in ieder geval geen naam-gebonden zoekacties doen, en service locater patterns (als er geen DI framework is) beperken tot t hoogstnoodzakelijke. Liever drag-n-drop ik alles aan elkaar via de designer. Maar ja, ik wil geen oordeel hebben over de programmeer stijlen van de anderen. Want misschien heb ik mijzelf een werkwijze in Unity aangeleerd die niet de meest productieve is, weet ik veel. Ik heb niet veel vanuit zelfstudies gewerkt, ik heb mijzelf gewoon Unity programmeren aangeleerd vanuit mijn jaren ervaring in Enterprise software development.
Rond 11 uur word ik het zat. Ik voorzie nieuwe functionaliteit die we heel slecht kunnen integreren zonder fatsoenlijk aan elkaar hangende code. Dus ben ik toch maar begonnen het DI framework, Zenject, te integreren. Ik weet niet of Zenject de oplossing is, maar ik weet wel dat wat er staat al gauw niet meer te houden is.
Het begint al laat te worden. We zijn ver voorbij de 22:00 die ik mijzelf als doel had gesteld om te stoppen. Ik heb heel veel moeite Zenject er in te krijgen, ze blijken een nieuwe versie met breaking changes te hebben en ik ben alleen bekend met de vorige versie. Om 01:00 geef ik het op. Rollback Zenject. Niet alleen vanwege de Zenject versie, maar t is gewoon te groot om in eens om te gooien en te veel code begint bugs te vertonen.

T belangrijkste wat we deze avond hebben bereikt is dat alles er beter uitziet. Betere graphics, de 2 karakters speelbaar, defender en attacker, alle endings… maar wel dus een kater van de code waar ik mij verantwoordelijk voor voel maar wat niet lekker loopt.
Dag 3
07:00
Ik moet vandaag op tijd komen vindt ik. Er moet nog zo veel gebeuren dat ik mij ertoe gezet heb er om 7 uur uit te gaan. Wel voel ik mij moe. Heel moe. Even overwoog ik zelfs de handdoek in de ring te gooien, door mijn code-kater van gisteravond gecombineerd met de moeheid en t vele werk wat nog wacht. Maar ik ga door, ik ga voor de ervaring en t ontmoeten van de mensen, niet voor het in 1x kunnen schrijven van een perfecte game.
08:00
Als ik aankom bij het gebouw is het stil. Ik word door de bewaking binnen gelaten. De gangen zijn verlaten. Ons hok is donker: Kees ligt er nog te slapen. Dan maar naar het ontbijt. Dat staat nog niet klaar. Ik loop terug en maak Kees wakker.. We zetten wat ramen open om de slaaplucht eruit te krijgen, en ik ga weer aan t werk.
Peter bleek zich nu echt verslapen te hebben, hij kan pas na half 11 komen vanwege t OV. Jammer, want hij was gisteravond juist goed bezig aan een bepaalde feature, maar die was nog niet af toen hij weg ging.
Jan is steady. Hij komt stipt na het ontbijt om 10 uur, net zoals gisteren.
We zijn lekker bezig. Iedereen zit in z’n focus zone. Ik ben druk bezig de gameflow in orde te krijgen. Er zijn her-en-der bugs die niemand er echt uit krijgt, ik fix ze door nieuwe aanpakken te implementeren.
Peter heeft problemen dingen op de juiste plek in code te krijgen. Ik voorzie nut van DI, dus ik probeer, nu met een helder hoofd, opnieuw Zenject er in te hangen. Maar dan alleen de hoogstnodige dingen in t DI framework te hangen. Dat slaagt in korte tijd.
We hebben veel last van merge conflicten. Unity heeft scene bestanden waar vanzelf veel werk in gebeurd maar die heel lastig mergen. Tel daar een slechte pull-push hygiëne bij op en je hebt recept voor veel frustratie en verloren werk. Frustraties beginnen op te lopen.

13:30 Eten
Snel weet wat van die belegde broodjes naar binnen werken. T valt mij op dat iedereen door blijft werken, even langs de gemeenschappelijke ruimte loopt om wat broodjes te halen, en daarna weer teruggaat.
14:00 Laatste loodjes
Nog 1 uur over tot aan de upload die van 15:00 tot 16:00 duurt.
We komen in een crisis terecht. Jan stelt terecht vast dat er nog behoorlijk wat schort aan de gameplay. Ik geef hem groot gelijk, maar geef ook toe dat hij degene is met t meeste gevoel ervoor en dat hij zelf met verbeteringen zal moeten komen omdat de anderen ze simpelweg niet zien. Ik mis Kees als backup, Kees was ergens anders in een hok gaan zitten om wat dingen te fixen vanwege concentratie issues. Ik probeer Jan op te beuren en geef aan dat we van heel ver komen en al veel bereikt hebben. Maar het mag niet baten, Jan geeft aan niet tevreden te zijn en niet zijn naam onder de game te willen hebben. Hij gooit de handdoek in de ring en zegt wel met wat dingen bezig te gaan die hij nog ziet liggen in t visuele design. Teveel stress.
Toch kwam deze bij mij hard aan. Ik hoopte iedereen aan boord te kunnen houden door gezamenlijke doelen te blijven formuleren, maar Jan had nu effectief aangegeven dat een gezamenlijk doel nog niet een goed doel betekent.
Ik zie ook de gameplay issues en de vele bugs. Ik was wat ongenuanceerd naar Jan toe dat ik geen gameplay gevoel heb, ik heb best een idee wat belangrijk is. Maar ik ga dat niet het team opleggen had ik mij bedacht… en bij dezen ben ik net zoals Jan niet daadkrachtig genoeg om het voortouw te nemen.
Ik verleg uiteindelijk toch maar de focus van mijn werk, van afronden van de features die we gezamenlijk afgesproken hadden tot nu dan maar ad-hock de feeling op orde krijgen. Maar niet in overleg met het team, dat durf ik niet aan met de spanning die er nu is.

Intussen blijkt dat de dead-line wat vloeibaarder is dan van tevoren gesteld, gelukkig. 17:00 is de max wat betreft de globalgamejam.org upload. Jurering gebeurd lokaal, om 17:30. We kunnen ons dus tot die tijd bezighouden met verbeteringen.

Wij beginnen met afronden / opruimen 
Team van ‘Thinking About Home’ 
Gang van de school 
Team van ‘Get That Bread’ 

Team van ‘Ithaca’ 
De gemeenschappelijke ruimte & plek van de playtests / jurering
17:30 Presentatie en bugs
Het is zo ver. We moeten de game presenteren. Er blijken een paar nasty bugs in geslopen te zijn in de laatste uren. Deel van de normale ending triggert niet, andere ending geeft aan dat je gewonnen hebt ipv verloren. Speciale ending werkt gelukkig wel. Gameplay wise hebben we een probleem: men kan zichzelf insluiten wat tot gevolg heeft dat we de game af moeten sluiten met Alt-F4… want we hebben nog geen menu/esc ingebouwd.
Maar er is nog meer: weinig aankleden van de level, actions werken maar half, actions hebben geen nut, AI biedt geen noemenswaardige tegenstand, geen noemenswaardige geluidseffecten/muziek.
Ik ben blij dat men uiteindelijk ons nog credits heeft gegeven voor onze ‘betere’ alternative-ending die verstopt in de game zat. En voor de koe. We wisten al dat die features mensen blij zouden maken, en gelukkig waren ze opgemerkt.
Afsluitend
Al met al ben ik heel tevreden met deze eerste gamejam. Veel nieuwe mensen ontmoet en connecties gemaakt. Werkwijzen van anderen kunnen zien en meemaken. Daar was het mij allemaal om te doen. Een werkende (soort van) game afgeleverd hebben was voor mij een bonus, en dat is ook behaald.

Maar ik was wel kapot. Van een normale werkweek direct door naar een gamejam, geen weekend, en toen weer een werkweek. Het was het waard.
Nog wat aanvullende gegevens, voor de geïnteresseerden:
- Registratie van ‘Cozy home – human vs cowman’ op https://globalgamejam.org/2019/games/cozy-home-human-vs-cowman
- Code van ‘Cozy home – human vs cowman’, met een paar bugs gefixt:
https://github.com/crappy-art-ggj-2019/cozyhome - De games van andere teams in Cibab Zwolle: https://globalgamejam.org/2019/games/thinking-about-home (winner)
https://globalgamejam.org/2019/games/ithaca (2nd)
https://globalgamejam.org/2019/games/knights-inferno (3rd) https://globalgamejam.org/2019/games/go-get-bread (5th) - De namen van mijn teamleden zijn gefingeerd. Er worden persoonlijke dingen genoemd, zo leest t voor hun net iets lekkerder.
